

Table of Contents
Picture This…
You’re sitting at your desk browsing the news and you see a head line something like:
(this is a real headline from Nov 2022)
You’re skeptical but you check out the AI startups demos and sure enough it looks like it could pass most first year university degrees with a 4.0.
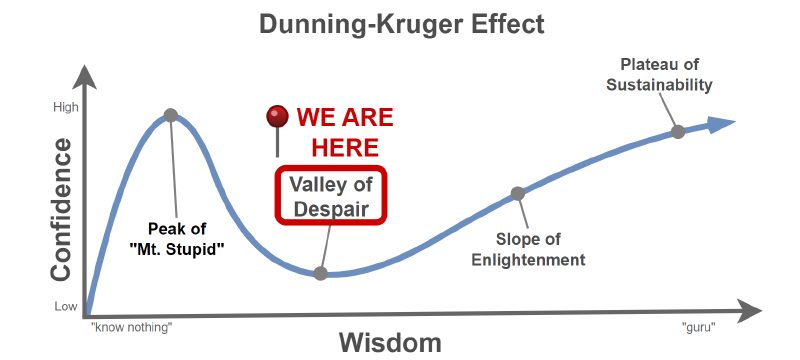
Now imagine you’re in a Masters of Data Science program, working on a lab that is writing a basic text generation model from scratch and you read the same headline. I suspect you would feel somewhere about here on the Dunning-Kruger curve:
You finally get to the magical moment you spent 5hrs getting to and it starts generating new text based on Taylor Swift lyrics and you have a hard time telling which are real and which are fake, try it for yourself:

(Answer at the end!)
Which lyrics do you think are fake?
This sparked myself and Jonah Hamilton onto the idea for a fun project!
Now you might be wondering how we achieved that and how simple was it REALLY? Well read on to learn something new!
Challenge: Build a text generation model from scratch and Tweet with it
Breaking this down into steps we needed to:
- Build a text generation model (in base python)
- Scrape sample text to train on (e.g. Taylor Swift lyrics)
- Setup a Twitter account and access the Developer API’s
- Deploy the models to Google Cloud to Tweet regularly
TLDR: It’s Alive and Tweeting like TSwift & Sherlock Holmes @mylittlemarkov!
Here are it’s latest tweets!
UPDATE April 2023: As you likely heard Elon Musk removed free access to the Twitter API, so now the account is kept up as a testament to the simplicity and power of Markov models.
Tweets by mylittlemarkovWe need YOUR help! What would you like to see @mylittlemarkov Tweet next? 🚀
Could be your favorite artist, author, movie star etc. or at least fun! If you put in your email you'll be notified when it goes live on the @mylittlemarkov Twitter account.
Tweet Generation: Markov Model
This idea originated from an Algorithms and Data Structures lab where we were asked to code the “training” of a Markov Model.
Attribution: the lab exercise was adapted with permission from Princeton COS 126, Markov Model of Natural Language. Original assignment was developed by Bob Sedgewick and Kevin Wayne and adapted for the Masters of Data Science program by Mike Gelbart. All code and figures unless otherwise attributed were created by Ty Andrews and Jonah Hamilton.
A Markov Model uses the text you give it and learns that for every unique series of N letters, e.g. N = 2, there are some letters which are more likely to follow some than others. For example, if you only look at any two letters such as “TH” and guess what letter follows it you’d likely say “E” or “I”. This is what a Markov Model does.
This is a bit hard to visualize so lets look at an example. Say we have text that contains “their there they’re” and an N of 3. We start by sliding across each N-gram of size 3 and counting the letters that follow.

Once we’ve slid across the entire text we have some N-grams with multiple letters and some with only one.
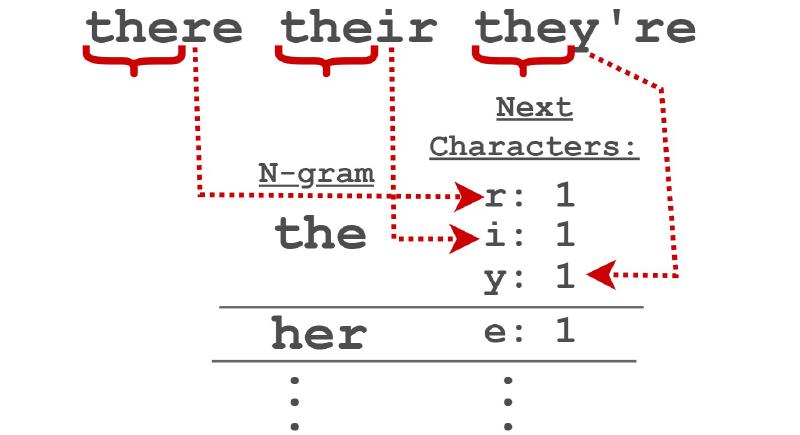
With these counts we generate the probability of each letter following that N-gram. So for the example “the” we see that each of “r/i/y” have a 33% probability of following the N-gram “the”.

So to code this we first start off by finding all the unique N-grams and counting which letters follow them.
Now that is a little messy using pure dictionaries. There are two useful data structures from the collections package, specifically Counter and DefaultDict which make our lives much simpler.
defaultdict- a dictionary like data structure which deals with a key not existing by creating it on assignment of a value to a new key. A default data type must be set as thedefault_factorymeaning when it creates new objects internally what data structure should they be.Counter- dictionary like object that on setting of a value will either initialize it if it doesn’t already exist and set to 1, or increment the value by 1.
As you can imagine this is exactly what we need, so using those two our ngram generation code can compress to this:
Then we normalize all those counts to get probabilities of the counted letters occurring.
And finally with these probabilities of N-grams and letters we can generate new text! All we do is tell it how many characters to generate. Then give it a starting N-gram which then is found in the dataset of N-grams and the following letter probabilities. Once a letter has been selected from the likely candidates the process repeats now with the new N-gram.
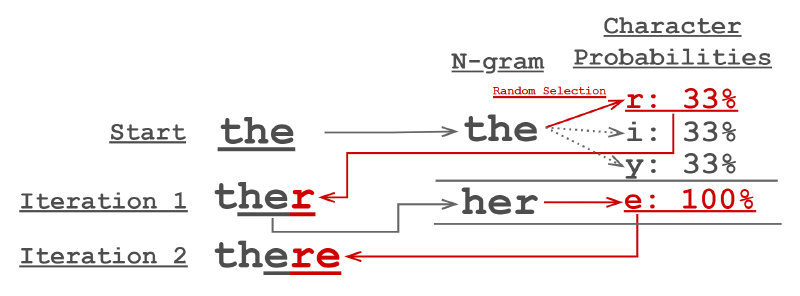
Markov Model text generation process.
The code to run the text generation is as follows:
Once all characters are generated you’ve just made your first text generation model!
Now after this is the hard part, ensuring the text is coherent! Here are some things we did to achieve decent results:
Tune the parameter N from 3-20 and inspect sample generated results
We had to be careful as too large of an N-gram and it just memorizes sentences, inspecting result at each stage helps thisTokenize useful two character symbols like new line “
\n” characters
Replacing “\n” with a “^” symbol before training then reinserting after generation worksTruncate generated text to natural finishing points
Since we generate until we have X characters, the ends of these strings don’t make sense. We find periods and new line characters and truncate after them.Writing custom model saving/loading functions to keep size of n-gram, weights etc. together
This also included start prompts for the model so it used real segments from the training data stored with the model to be used upon generation.
Now with all of this we get to pick some text to train on! We started with the following corpuses:
- Taylor Swift Lyrics - as you saw above, we found a dataset of all of Taylor Swifts lyrics publicly available HERE
- Trumps Tweets - again a nicely compiled list of all of Trumps Tweets is available HERE
- All of the Sherlock Holmes Books: Sir Arthur Conan Doyle - we found a public compiled document that included all of his texts
To attempt to visualize the absurdity of these we got a computer generated image from OpenAI’s DALL-E 2 image generation demo given the prompt: “A blond female singer in her 30’s, an orange faced politician in his 70’s and Sherlock Holmes are sitting on a red couch on a tv show arguing with each other in hyper realism.”

Twitter Bot: Tweepy & Twitter Developer API
With the Markov Model up and running the next task at hand was to connect to the Twitter API. Lucky for us there is a ready-made Python library that is designed exactly for this purpose called Tweepy.
Using Tweepy greatly simplifies the process of authentication and interaction with Twitter API. Tweepy allows users to easily do anything you normally might do on Twitter but with the added benefit of being able to programmatically define how and what those actions might be.
Before we could get our bot fired up, we needed to obtain access to the Twitter API. The process is well documented online and a step-by-step process can be found HERE, but the main points are listed below.
- Sign up for a Twitter developer account
- Create a project for your application
- Apply for “Elevated Access” to be able to to tweet and not just scrape tweets
- Generate your Twitter API Credentials
- Using Tweepy connect to the Twitter API using the above credentials
Like most things in life when something seems straightforward it rarely is (especially in the world of programming). Building the bot was not too much of a hassle given we had access to Tweepy but authenticating to the API with correct credentials was a bit of mucking around so we hope we can save you some of that should you want to do this in the future!
Below is the code that we were able to authenticate correctly with.
And finally the actual sending of the tweet is quite simple, this is all that’s needed once you’ve authenticated!
Deploy: Cloud Run and Docker
Now pulling all the pieces together there were 3 main pieces to deploying this:
- Randomly select one of the trained models and generate the Tweet
- Authenticate to the Twitter API and send the Tweet
- Schedule this to run every hour from 9AM - 9PM 7 days a week
The source code found in the my-little-markov-model GitHub repository was packaged up into a Docker image with the entry point just being the main.py file which kicks off the generation and Tweeting.
Googles Cloud Build service was used for managing builds and storing in Google Artifact Registry. From Artifact Registry the newly built image is selected and deployed to a Cloud Run instance.
All of this is orchestrated in the cloudbuild.yaml file, you can see the steps above outlined below:
Googles secrets manager is used to expose the Twitter API keys required securely as environment variables.
And FINALLY we use Google Cloud Scheduler to run the container to Tweet every hour from 9AM to 9PM. I found a useful guide on how to write CRON scheduling commands and so here is ours used with the reference above.
Which Taylor Swift Lyrics Were ACTUALLY Fake?
First of all THANKS if you made it this far. We hope you laughed or at least learnt a little something new.
Please suggest a new text topic to train on and we will get the account Tweeting with it as soon as possible!
We need YOUR help! What would you like to see @mylittlemarkov Tweet next? 🚀
Could be your favorite artist, author, movie star etc. or at least fun! If you put in your email you'll be notified when it goes live on the @mylittlemarkov Twitter account.
And the moment you’ve all been scrolling for: Lyrics 1 were generated by the Markov Model

