

Strava Snooping
For more than the last 10 years I trained and raced competitively in road, mountain bike and track cycling. Throughout this time I used a wide array of performance tracking tools like TrainingPeaks, GoldenCheetah, etc. The one that has stuck with me though is Strava.
If you’re unfamiliar with the world of activity monitoring, Strava services over 55 million users for being a training and virtual competition platform. Athletes from around the world run, ride and swim along the same routes as one another and their times for those segments are compared on a leaderboard. In recent years Strava has grown to an annual revenue of over 72 million dollars from its Premium subscription service for tracking and monitoring performance.
Stravas user statistics are impressive:
- 3 Billion activities uploaded in 2020
- 11.2 Biillion kilometers recorded in 2020
- 80% of users are outside the US
- 20 activities are uploaded every second
This got me wondering…
What does Strava know about me from my uploaded activities?
My Data
To try and figure this out the most reasonable point was looking at my own data. Since I’ve been a regular user for more than 5 years uploading nearly all my activities it’s a substantial amount of information.
To get your data out of Strava I found two options.
- A bulk export of all the raw GPS and .fit files along with other basic information which is nicely provided by Strava.
- Manually exporting the summary of exercises one page at a time in JSON format.
For this initial analysis I only wanted high level activity info (activity type, start times, length, distance etc.). Luckily I found this slick post from Scott Dawson, a UX Designer from New York, who figured out how to get all activity info in a single export: How to Export Strava Workout Data.
This results in a CSV with the following information:
- Activity Name: Chosen name for the activity or defaults of “Morning Ride” “Afternoon Run” etc.
- Activity Type: The sport or activity type e.g. Run, Weights, Hike, etc.
- Gear ID: The gear you used and entered into Strava for tracking wear etc.
- Start Date & Time: Pretty self-explanatory!
- Moving & Elapsed Time: Moving time is determined by Strava based on GPS or other speed sources, elapsed time is total recording length
- Elevation & Calories: The total elevation that was gained and calories burned, don’t know exact method for the calorie estimation
Predicting if Users are Employed
I wondered if Strava was able to determine which of their users are employed. This could be extremely useful in evaluating the proportion of their user base that have higher disposable income and thus most likely to subscribe to the Premium service.
To try and see this, I know that in my data from 2014 - 2018 I was in school with a flexible schedule and training semi-proffessionally. In 2018 I graduated with my degree with Honors in Mechatronics Engineering from the University of Victoria and began my career at the sports tech and IoT company 4iiii Innovations Inc.
Therefore, I should be able to see a significant difference in my activity’s between those two time periods.
Hypothesis: If a users mid-week activities commonly start outside of work hours (9-12AM, 1-4PM) they are working
Initial Exploration
I started this off by looking at individual years and how my weekly activities changed by hour of the day. You can see in the following graphs that my weekday habits are significantly different from weekends and there is noticeable undulation in the profiles on weekdays.
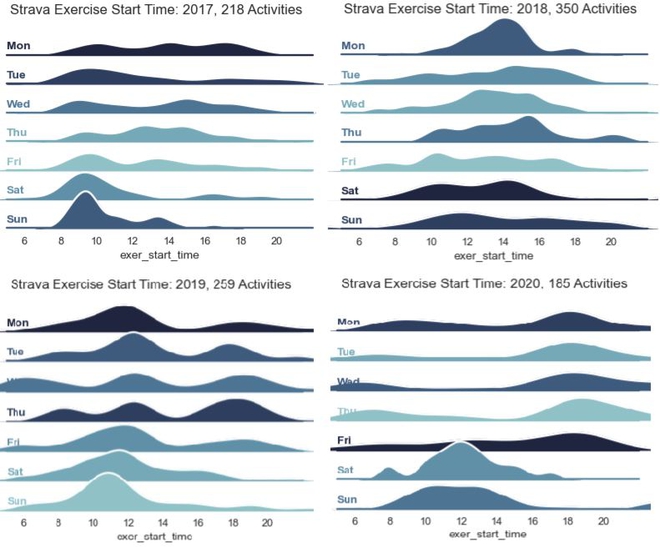
First look at weekly data.
To see if this was realistic I grouped each year’s weekday activities by start time. Converting those into a percentage of total weekly activities to account for weeks with varying numbers of activities. Splitting out the two reference time frames it’s pretty clear that while I was training and in school my activities commonly started during work hours and when working there are significant peaks at lunch and right after work.
Here is what the yearly average data looks like for when activities began during the week (Mon-Fri).
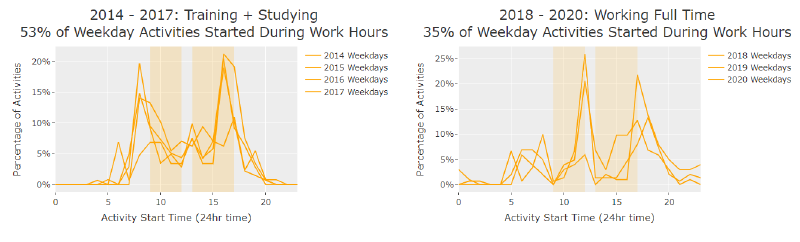
Week day start times across the years I was working and not working.
As you may expect, my weekend activities consistently started around 9-10 in the morning, Strava knows I’m not an early riser!
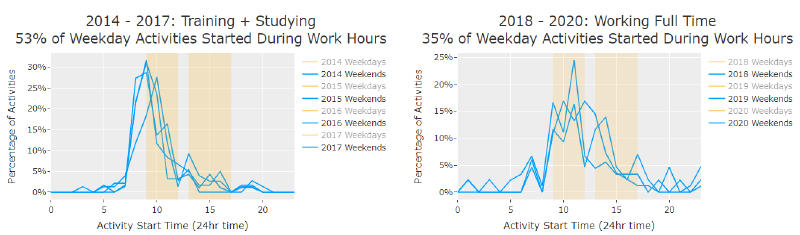
Weekend start times following a pretty clear pattern.
Building the Model
To build a predictive model I first thought of the time frame over which Strava might want this information. Monthly seemed like a reasonable starting point to balance having enough data while being able to make actionable changes to marketing plans, future earning reports etc.
Feature Selection
Feature selection for Logistic Regression is susceptible to the 1-in-10 rule of thumb in which the number of features should be approximately 10 percent of the positive labelled data (employed). Since I have ~40 employed samples I’m going to break the rule and have 2 features, percentage of activities during morning work hours (9-12AM) and afternoon work hours (1-4PM). This also has the added benefit of being able to easily visualize the models results through a heat map of the class confidence of it’s predictions, more on this later.
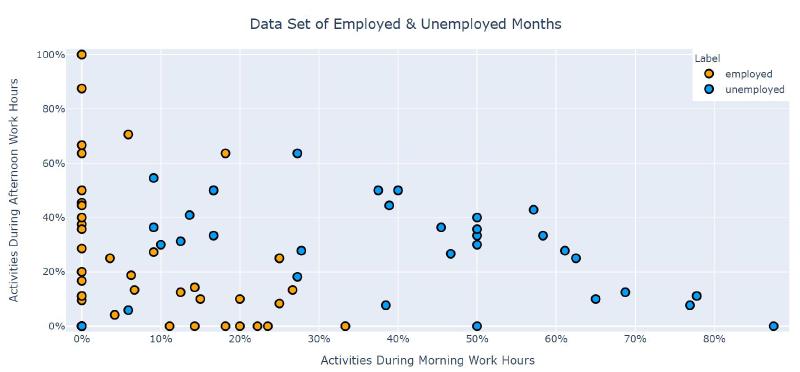
Full data set from feature selection.
Model Selection
The main factors considered for model selection is the small data set available for testing (~70 months of data). As is common with small datasets overfitting will be an issue. The dataset is also unbalanced with more unemployed data points than unemployed. Logistic Regression was chosen as the starting point as it’s simple to train, simple to regularize and quick to train.
In addition to logisitic regression I wanted to see how a gradient boosted model such as XGBoost would perform on this small of a data set and how easy/hard it would be to regularize and not overfit. I recently discovered LightGBM (Gradient Boosted Machine) which as you can tell, is a lighter weight version of gradient boosting that uses leaf wise tree growth. This is different from typical XGBoost which use level-wise tree growth. Their are many great articles comparing XGBoost and LightGBM like this one Which algorithm takes the crown: Light GBM vs XGBOOST? by Pranjal Khandelwal].
But what this means for us is that a LightGBM model will:
- Train Faster and with Higher Efficiency: Light GBM use histogram based algorithm i.e it buckets continuous feature values into discrete bins which acclerates the training procedure.
- Achieve Better Accuracy than any other Boosting Algorithm: It produces much more complex trees by following leaf wise split approach rather than a level-wise approach which is the main factor in achieving higher accuracy. This leads to overfitting and will need be monitored for this experiment.
- Reduce Model Memory Usage: Replaces continuous values to discrete bins which result in lower memory usage.
Model Training
I used k-cross fold validation on the training data set split into 5 folds. For the logistic regression model I used L2 regularization to try and prevent overfitting which ended up not being a major concern for the logistic regression model.
The LGBM model on the other hand proved significantly more difficult to train to a reasonable result. The hyper parameters I tuned were:
- Number of Leaves: the maximum number of leaves generated, this is the main parameter
- Max Depth: limits the tree depth to help prevent overfitting
- Number of Iterations: this controls the number of boosting rounds performed, since LGBM uses decision trees as the learners this is synonymous with setting the number of trees generated
The highest training accuracy for LGBM achieved was 81% and even TRYING to overfit the model by increasing all parameters didn’t yield better results.
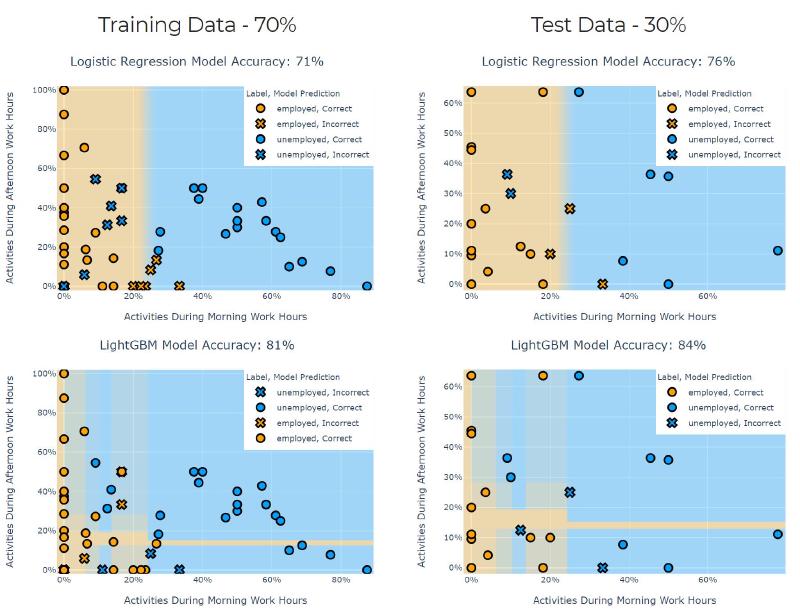
Logistic Regression and LGBM model results.
Did it work?
It appears that it is possible to estimate whether a person is employed or not from when their activities start. The caveats with this is that they are regularly uploading to Strava on a monthly basis and they follow a traditional work schedule.
Although this would likely be “tricked” by people with non-standard work days I think it would still be valuable for Strava to be able to see the relative proportion of their users working.
Improvements & Next Steps
First and foremost being able to get more data from another person knowing when they were working/not would greatly improve the analysis, either to improve generalization or disprove that there is any correlation.
Feature engineering in the form of whether including activities started outside work hours may be useful to discern between individuals who just have an erratic schedule, or those that truly do only exercise outside of work hours.
Another avenue if I could access more data I would try using percentage of activities started in every hour of the day (24 features) and pass that through a dense neural network to see if it’s able to learn from all the varieties of peoples habits who are employed/unemployed that are not so “logical” from a human perspective.
Next I’m going to try and recruit people to send me their data and add to my analysis so if you’re interested please get in touch! Otherwise trying some of the above feature engineering variations may be interesting!
Play with the Results & Data
To make this project a bit more interesting I built an entire dashboard to show some of the results and analysis.
To do this I used:
- Plotly Dash: a web based graphing library for building production grade apps
- Dash Bootstrap: a templating and customization library for building interactive web pages
- Google App Engine: to deploy the site I decided to go with App Engine as it appears more full featured than Heroku and I’m interested in getting more hands on with the Google Cloud Platform
Here is the link to the working analysis dashboard for this work.
www.stravasnooper.com
Stay tuned for more info and progress updates and follow me on LinkedIn or GitHub below.
GitHub: tieandrews LinkedIn: Ty Andrews

