

Pottery Problems Solved by Computer Science
A couple years ago my brother Dustin and I got into doing pottery and after the first 5-6 months our problems turned from how do I stop making rainbows (name for messed up pieces you let sit to dry the clay) to what is something cool and useful I should make? This often resulted in browsing Instagram for inspiration from some some amazing artists such as @samknoppceramics. The saying “good artists copy, great artists steal” came to mind but begged the question, can you borrow peoples art yet not be stealing a piece of their hard work?

Recently I started to dive into how you can use code to generate images of people, music and spoken or written mediums. I thought this would be a great problem for these techniques to solve by generating new and novel pottery designs which we could then make in the pottery studio.
Why Generative Adversarial Networks?
The state-of-the-art way to generate hyper-realistic images is using generative adversarial networks (GAN) which pit a Generator model, which generates images, against a Discriminator model, which says whether the Generator created an image that actually looks like the thing you want to create. The Generator takes in a randomized set of inputs, feeds those through the model, which then outputs a truly never before seen image.
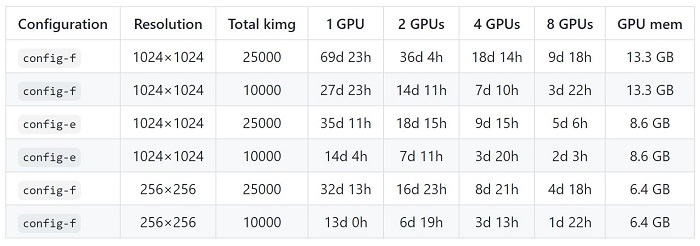
Existing state of the art models are being used to generate peoples faces (This Person Does Not Exist) or novel chemical compounds (This Chemical Does Not Exist). The common model for images is StyleGAN which produces the faces seen in This Person Does Not Exist. One interesting and key part to applying it to other domains is that the training for StyleGAN has some pretty hefty training times on the order of days to weeks on decent GPU’s. Below is the benchmarked training times from the official StyleGAN2 Github page (StyleGAN2 Github).
There is a project titled This Vessel Does Not Exist which has used images available from the Metropolitan Museum of Art along with scraping images from auction houses and Flickr to build out a dataset of ~38,000 images. This project uses the StyleGAN1 and StyleGAN2 to build the GAN and does an amazing job! This doesn’t satisfy us though because although we would like to be able to recreate 12th century Ming vases, that’s a bit out of our reach so some nice hand thrown pottery ideas will still be very useful!
Finding Training Data
Typically GAN’s perform best with tens of thousands of manicured images to produce the hyper-realistic results shown in things such as This Person Does Not Exist. Approaches consist typically of a combination of opens source datasets such as the Metropolitan Museum of Art along with various web-scraping sources. As this project is completely personal and no commercial aspirations we will likely use a combination of these two approaches to build our data set but first it will start with our own pottery images from our most recent classes!

The key is to reduce variation in background, relative size and location of the pottery (i.e. not a small mug in a full sized image) and for best results controlling significant structural variations can allow the model to truly learn what makes a bowl a bowl. This may allow for more crisp and unique generated designs or may just produce a lot of very similar designs, we’ll soon find out!
Data Prep: Object Detection & Cropping with YOLOv4
After gathering a couple thousand images including pottery mugs, bowls and vases like the one below, we recognized we needed to be able to crop the image around the mug/bowl/vase as in some instances there was quite a bit of backdrop in the nicely taken photos.

Luckily at the time of doing this, the updated YOLOv4 framework was released and we had a reason to try it out! Github link HERE. We took every image, used the “mug”, “cup”, “vase” and “bowl” labels in YOLO, and cropped each image to a square based off the location of the bounding box. Taking the sample image from above, this is what the output looked like.

As you can see it handles having other mugs in the image fairly well although there were cases where the cropping and image classification showed some not so great results.
GAN Structure & Resolution
To decide on what structure to use for the GAN at first we looked to the reference code from the great book Generative Deep Learning: Teaching Machines to Paint, Write, Compose & Play which has a relatively simple structure (when compared to StyleGAN) they use for demonstrating GAN’s for generating celebrities faces using the Celeb Faces Attributes (CelebA) dataset.
The specific flavor chosen was a Wasserstein GAN with Gradient Penalty (WGAN-GP) and it’s two primary additions over a standard GAN are:
- Wasserstein Loss: this loss equation helps reduce the sensitivity to tuning parameters which can cause exploding/vanishing gradients during training
- Gradient Penalty: this constraint on the gradient helps to enforce the Lipschitz constraint which helps ensure the model can converge quickly while again preventing vanishing/exploding gradients
We used the following structure for the Critic portion of the GAN.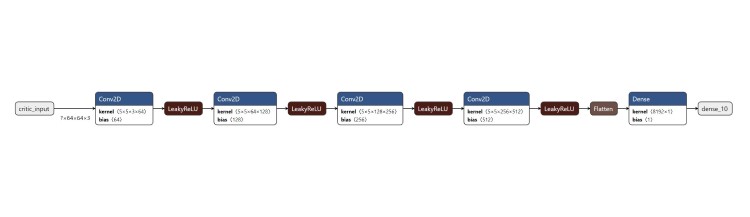
And the following structure for the Generator.
We chose to do some initial testing with an image resolution of 64x64 pixels to help keep training times reasonable and allow more experimentation with structure etc. earlier on. After looking at some of the cropped images dropped down to that resolution it looked like it should be able to learn what mugs/bowls/vases look like at this resolution. Below are some of the cropped training images at 64x64 resolution.

Training: One GPU & ~20k Epochs Later
We got the model setup to train locally on a Nvidia GTX 1060 which took per epoch training time from ~90 seconds on the CPU down to ~10 seconds.Letting this run for a couple hours gave a decent sense of how the model was looking with some intermediate images to check in on it as well as monitoring the losses for both discriminator and generator.
Watching the progression of the model was remarkable below are snap shots along the way of what the generator was producing.
After 500 epochs, <1hr training.

After 5k epochs, ~6hrs training.

After 10k epochs, ~12 hrs training.

After 17k epochs, ~20hrs training.

If you look at the generated images closer it becomes clear the 64x64 resolution may be limiting the GAN’s ability to display/learn details. Although the details are visible in the original 64x64 images, it appears the variability in the training images orientation, gackground and coloring is too great to get to highly realistic images.
It is promising that multiple images appear recognizable as a mug or ceramic to a somewhat trained eye, but it’s by no means good enough!
Here is a time-lapse of the training sample images generated where you can see it converge and also diverge at certain points throughout the training.
Stay tuned for more info and progress updates and follow me on LinkedIn or GitHub below.
GitHub: tieandrews LinkedIn: Ty Andrews
